
Every day, enterprise brands generate thousands of creative assets across multiple channels, platforms, and campaigns. A single brand guideline violation can cost millions in reputation damage, legal penalties, and lost consumer trust.
Here's the problem: manual compliance review doesn't scale. Human reviewers manage only 50-100 creatives per day at 85% accuracy under time pressure.
Rocketium's AI compliance system processes 10,000+ creatives daily at 90%+ accuracy. It uses a dual-intelligence architecture that combines analytics-driven insights with real-time rule evaluation.
We've analyzed 200,000+ historical creatives to provide contextual recommendations. Logo detection uses SIFT feature matching for rotated/distorted images and Google Vision API for speed. Mathematical precision through Euclidean distance calculations, trigonometric transformations, and geometric analysis makes every compliance decision objectively verifiable.
This isn't incremental improvement. It's a fundamental reimagining of brand governance through distributed intelligence, computer vision, and mathematical precision.
Overview
This article walks through the complete AI compliance system in five parts.
We start with the brand compliance crisis. Manual review doesn't scale, and the consequences of violations are severe. You'll see why naive template enforcement fails for modern brand guidelines.
The core of the system is a dual-intelligence architecture. Two complementary engines work together. One learns from historical data to establish benchmarks, the other validates creatives in real-time using OCR, machine learning, NLP, and computer vision.
Logo detection is particularly interesting. We built two approaches for different scenarios. One prioritizes accuracy for rotated or distorted images. The other prioritizes speed for real-time feedback. Multiple AI technologies work together through intelligent intersection, and brands can define compliance rules without writing code.
Cost optimization matters too. Different use cases need different approaches to balance speed, accuracy, and cost.
The last section covers what's coming next. Multimodal transformers, natural language rule authoring, and predictive compliance scoring will make the system even more powerful.
Let's start with the problem.
The brand compliance challenge
Brand compliance means adhering to specific guidelines that ensure consistency across all creative touchpoints. These guidelines cover logo usage, typography, color palettes, imagery, messaging tone, and legal requirements.
Non-compliance creates real business risks.
Consider the Volkswagen emissions scandal. The company marketed diesel vehicles as eco-friendly, but software manipulated emissions testing results. When exposed, Volkswagen faced $30 billion in fines, massive reputation damage, and criminal charges. While this represents regulatory compliance rather than creative compliance, it shows what happens when guidelines get violated.
The creative compliance challenge is different but equally critical. A financial services brand with 50 regional teams producing 10 campaign variations across 30 ad formats generates 15,000 unique creative assets quarterly. Manual review at 15 minutes per asset requires 3,750 hours. That's 93.75 weeks of full-time work for a single quarter's output.
This doesn't scale. And naive template enforcement or simple color-matching fails when faced with the nuanced requirements of modern brand standards.
Common compliance requirements
Analysis of e-commerce platforms and major brand websites reveals consistent patterns. Brands typically enforce:
Spatial rules - Logos positioned at corners or center; terms and conditions in small font at bottom corners.
Hierarchy requirements - 40-50% white space for visibility; character count limitations.
Reserved zones - UI elements occupying fixed portions where creative elements can't appear.
Color governance - Approved palette enforcement; contrast ratio requirements.
Content restrictions - No designation mentions; gender and diversity neutrality; alcohol prohibition in certain contexts.
Typography standards - Font family restrictions; minimum legibility thresholds; title vs. sentence case rules.
These requirements form a complex web of interdependent rules that must be evaluated simultaneously across multiple creative elements.
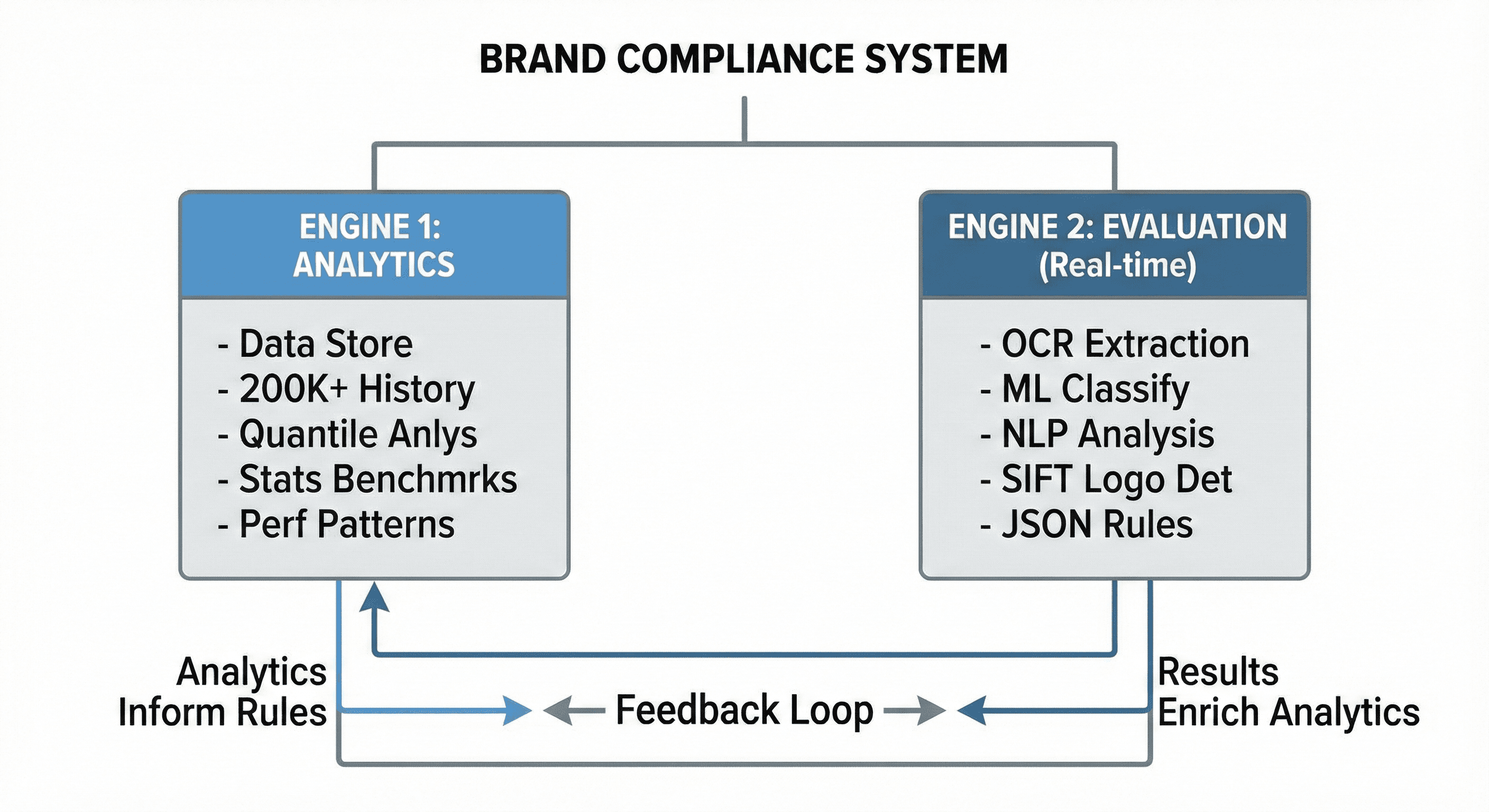
The dual-intelligence architecture
Different aspects of brand governance require different types of intelligence. When we built Rocketium's compliance system, we used two complementary engines working together.
Here's how they connect:
The analytics engine
The analytics engine stores and analyzes creative data at scale. It turns raw design files into insights about what works. This engine processes data from 200,000+ creatives to establish performance baselines and identify outliers.
The evaluation engine
The evaluation engine validates individual creatives against brand-specific rules in real-time, providing immediate feedback to designers. It combines multiple AI technologies (OCR for text extraction, machine learning for element classification, and NLP for content analysis) with a JSON-based rule execution framework.
Together, these engines form a feedback loop. Analytics inform rule calibration, while evaluation results enrich the analytical dataset.
Deriving insights through statistical analysis
The analytics engine doesn't just store data. It transforms it into actionable compliance recommendations through quantile analysis.
Consider the requirement "Logos should not exceed recommended size ratios." Rather than imposing arbitrary thresholds, we analyze historical performance. We query the analytics database for three key calculations.
Calculate actual visible area for each logo element (accounting for padding/margins)
Aggregate total logo area per creative
Compute 100 percentiles of logo area distribution across all historical creatives
Here's how it works in practice
We analyzed thousands of past creatives and found this logo size distribution:
25th percentile: 2.1% (only 25% of logos are this small or smaller)
50th percentile: 3.5% (half of all logos are smaller than this, the median)
75th percentile: 5.8% (75% of logos are smaller than this)
90th percentile: 8.2% (90% of logos are smaller than this)
This creates a "normal range" based on real performance data.
Now say a designer creates a new ad where the logo occupies 12% of the canvas. Comparing 12% against the historical distribution shows that the 90th percentile is only 8.2%. This means 83% of all successful past creatives used smaller logos.
The system responds: "83% of creatives have logos smaller than yours. Consider reducing logo prominence."
Why this matters
Instead of arbitrary rules like "logo must be between 3-8%", we use actual performance data from 200,000+ creatives. Recommendations are based on what actually works for that brand.
Analysis happens at two levels. Queries analyze only creatives from the same organization, providing brand-specific norms tailored to that company's historical performance patterns. Queries across the entire dataset establish industry-wide benchmarks, useful for brands without extensive historical data.
Recommendations reference both. "Your logo occupies 12% of canvas. Within your brand, 89% of creatives use smaller logos. Across all brands in your industry, 76% use smaller logos."
Technical implementation
Building the evaluation engine
While analytics provide contextual intelligence, real-time compliance validation requires a different approach. It must extract, classify, and evaluate creative elements within seconds.
Logo placement and sizing represent one of the most critical compliance requirements across brand guidelines. A misplaced or incorrectly sized logo can undermine brand recognition and violate strict corporate identity standards.
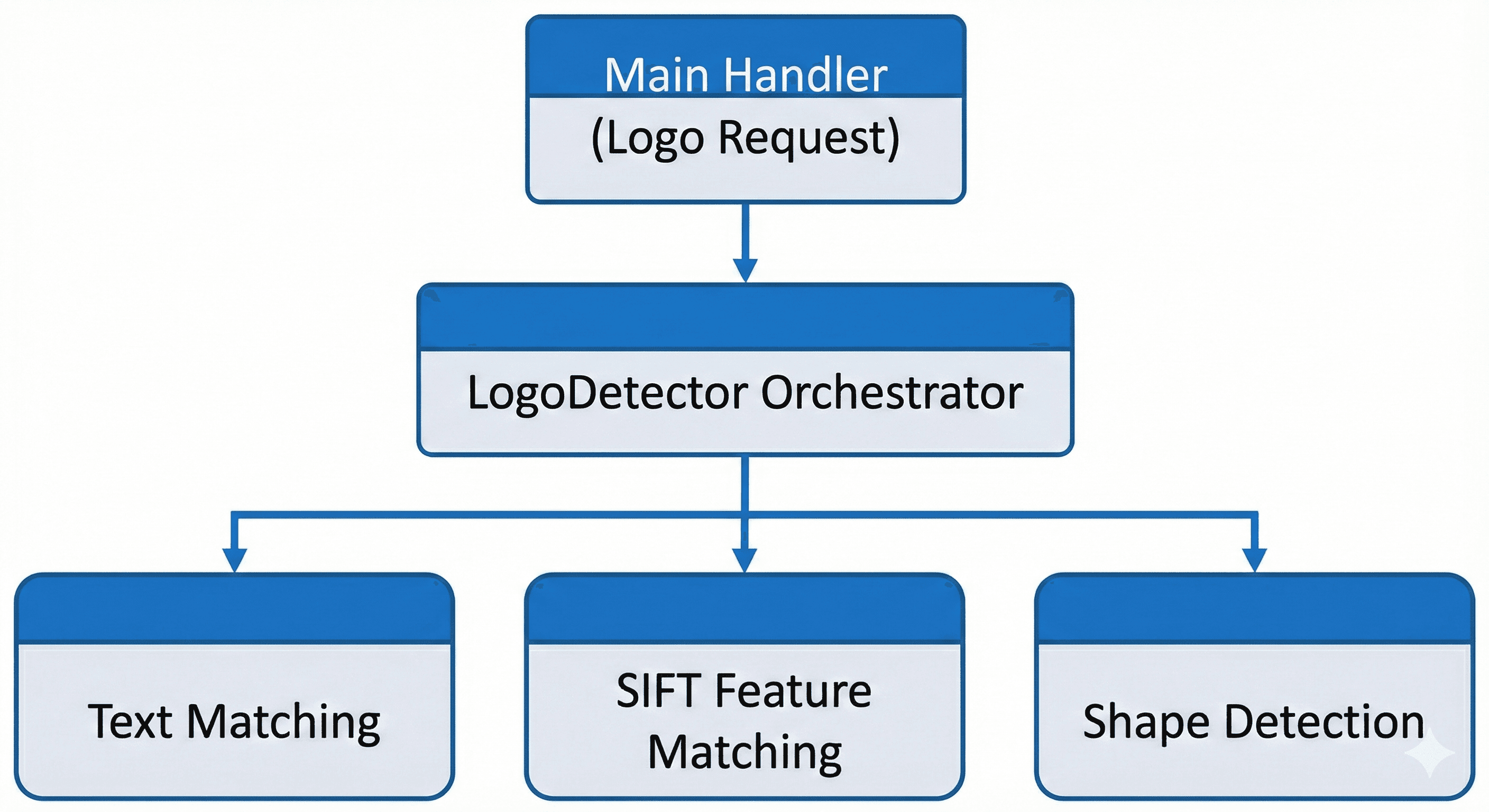
Turns out, logo detection isn't straightforward. We implemented two complementary approaches, each optimized for different accuracy-speed trade-offs.
Approach 1 - Advanced SIFT-based detection
The sophisticated approach combines text matching, Scale-Invariant Feature Transform (SIFT) feature detection, and geometric shape analysis for precise logo identification in challenging conditions like rotated images, distorted perspectives, and partial occlusions.
1. Text region detection
Extract text annotations from Google Vision API, identifying potential logo text components. For multi-word logos (e.g., "Mercedes Benz"), the system merges adjacent bounding boxes.
2. Expanded cutout creation
Generate expanded regions around matched text using logo proportions. This accounts for graphic elements surrounding logo text.
Expansion distance formulas



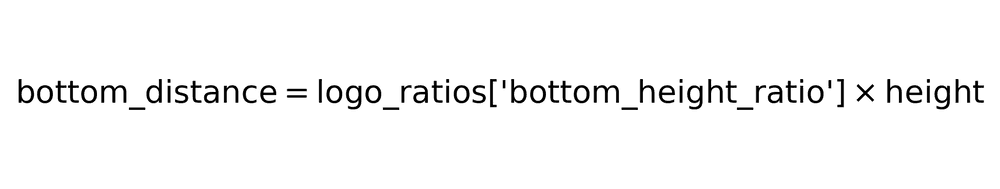
For rotated bounding boxes, the system calculates rotation angle and applies perspective transformation.
Rotation angle
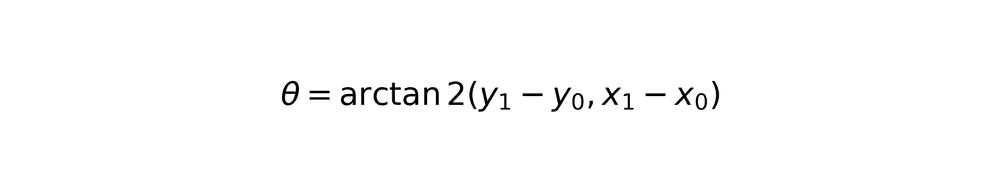
Rotated bounding box dimensions
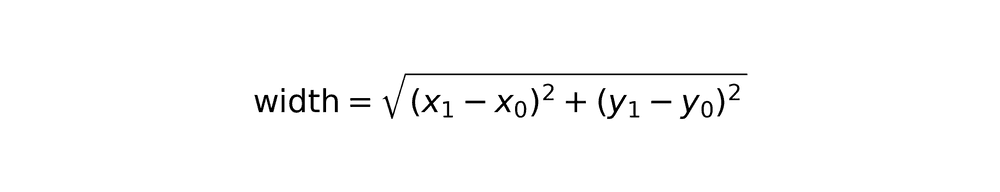
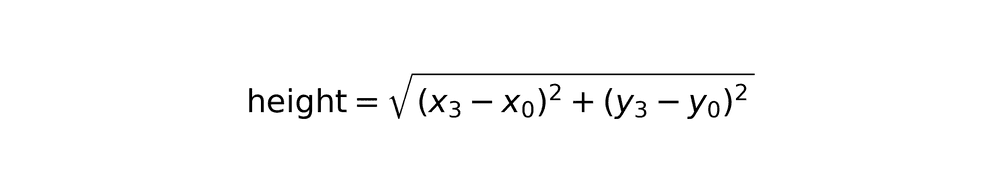
3. SIFT feature extraction and matching
SIFT (Scale-Invariant Feature Transform) identifies distinctive keypoints invariant to scale, rotation, and illumination changes. The algorithm extracts features from both reference logo and candidate cutouts, then matches them.
SIFT similarity score calculation
The algorithm calculates a match ratio based on good matches (those passing Lowe's ratio test):

It computes a quality factor based on average matching distance:
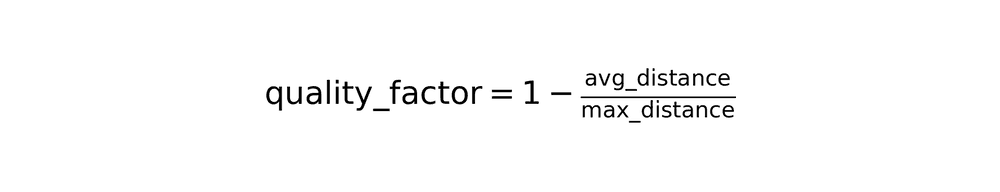
These combine into a raw score:

A sigmoid transformation normalizes the score to [-1, 1] range:
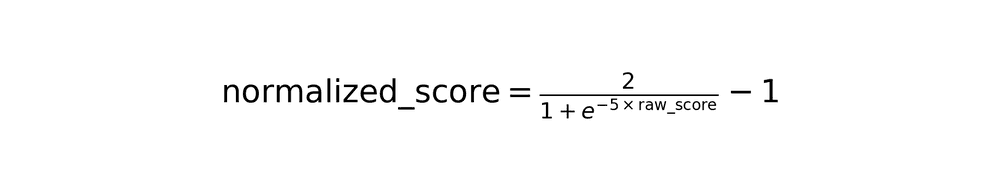
This sigmoid normalization makes scores cluster near -1 (poor match) or +1 (excellent match), creating clear decision boundaries.
4. Geometric shape detection
Supplement feature matching with shape analysis to detect logo containers (circles, rectangles, ellipses, triangles).
Circularity calculation (distinguishes circles from other shapes).
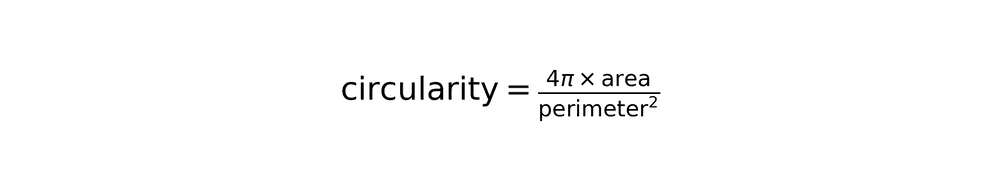
Perfect circle: circularity ~ 1.0
Rectangle or irregular shape: circularity < 0.8
Ellipse eccentricity (measures elongation).
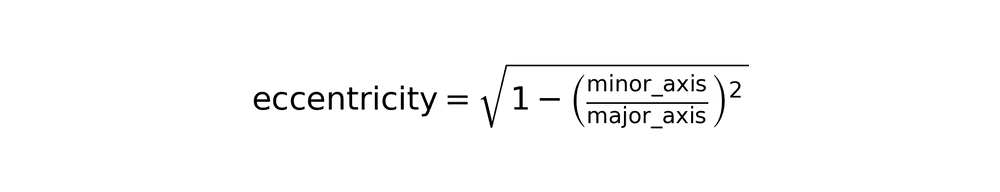
Circle: eccentricity = 0
Elongated ellipse: eccentricity approaches 1
For detected ellipses, the system calculates parametric boundary points.
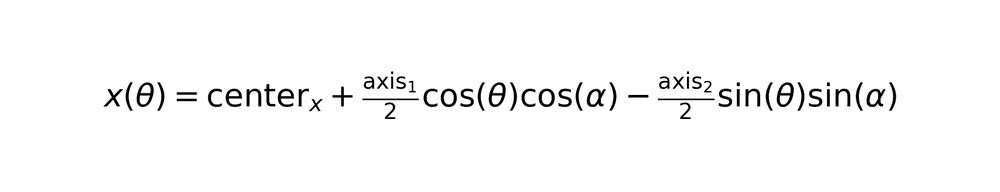
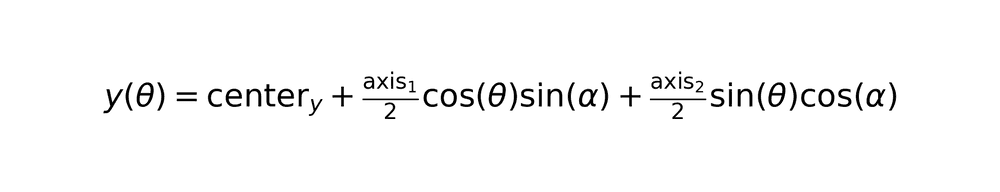
where α represents rotation angle in radians.
5. Confidence scoring and output
Combine SIFT scores, shape detection results, and text matching confidence into final logo detection output.
Approach 2 - Fast Google Vision API detection
For real-time workflows requiring immediate feedback, the streamlined approach uses Google Vision API's built-in logo detection with intelligent post-processing.
1. API logo detection
2. Confidence filtering
Apply minimum confidence threshold (80%) to eliminate false positives.
3. Intersection-based filtering
Remove logos incorrectly detected within other objects (except persons and specific edge cases). This prevents false positives where brand elements on clothing or products get misidentified.
Rectangle overlap calculation
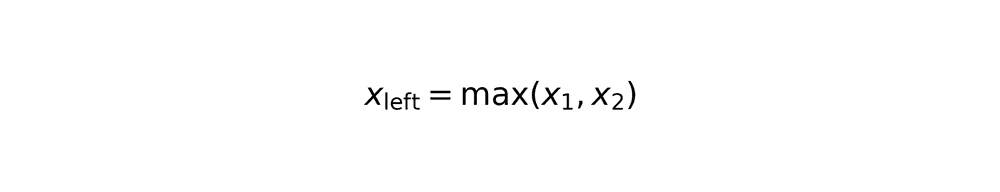
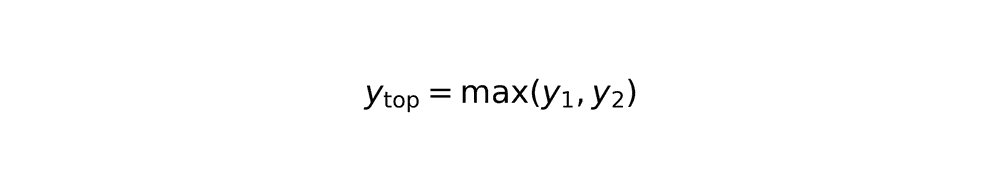
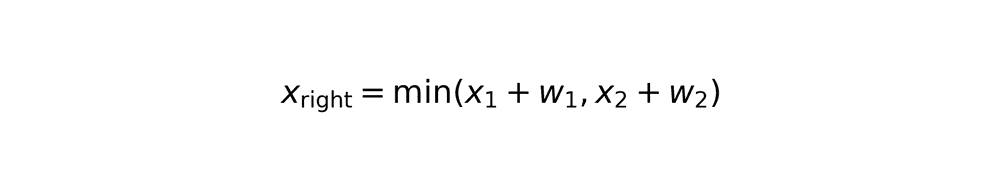
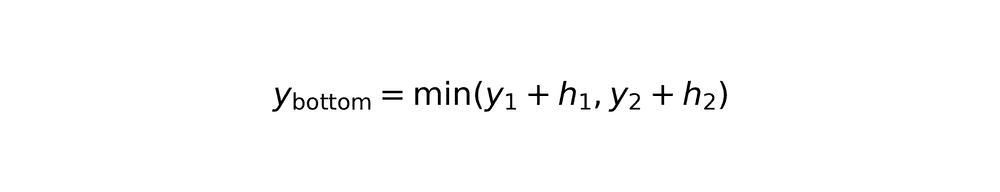
Overlapping area
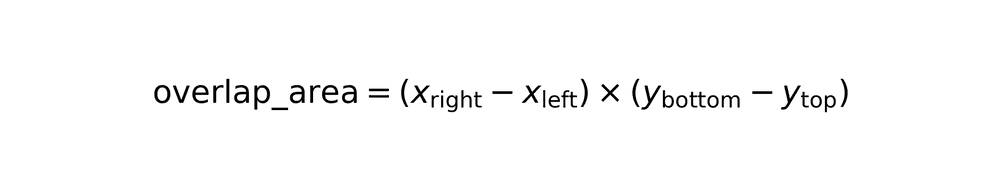
Overlap percentage
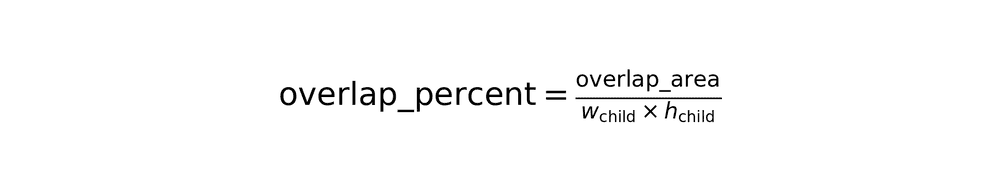
Subset determination
A logo is considered a subset of another object if:
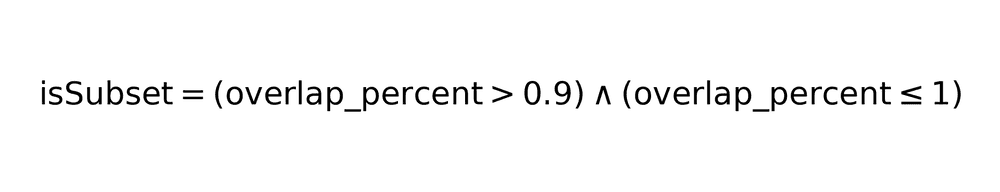
This 90% threshold filters only truly contained logos, while maintaining boundary logos.
4. Normalized position extraction
Convert absolute pixel coordinates to normalized percentages for size-independent representation:
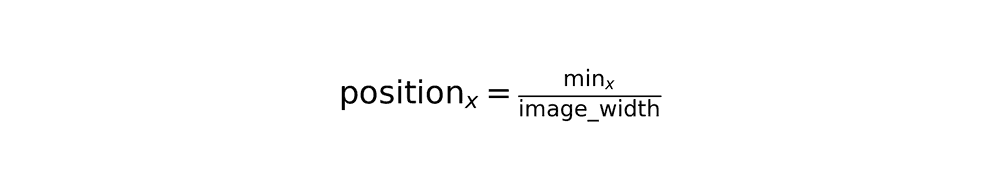
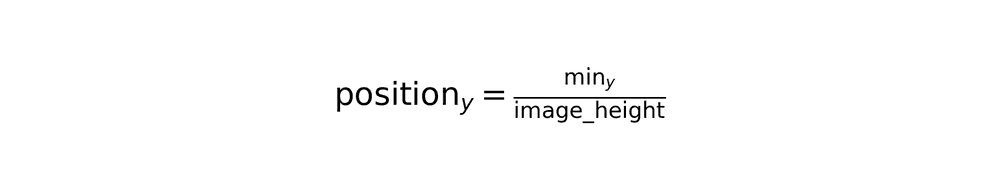
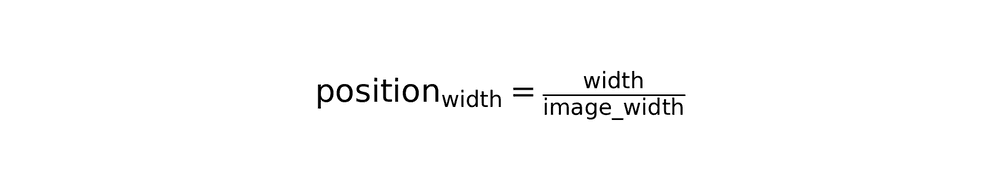
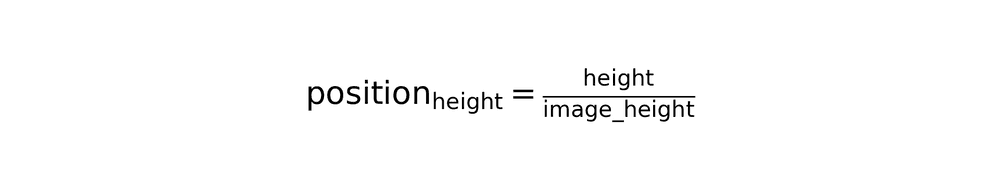
Area percentage calculation

When to use each approach
REQUIREMENT | ADVANCED SIFT | FAST VISION API |
|---|---|---|
Rotated logos | ✅ Excellent | 🤷♂️ Limited |
Partial occlusion | ✅ Robust | 👎 Fails |
Speed (ms) | 800-1200 | 150-300 |
Multi-word logos | ✅ Supported | 🤷♂️ Variable |
Custom logo training | ✅ Full control | 👎 API-dependent |
Cost per 1000 images | $0.80 | $1.50 |
Use Fast Vision API for real-time designer feedback, standard orientations, and high-quality source images. Use Advanced SIFT for batch processing, rotated or distorted images, custom logo databases, and cost-sensitive workflows.
Three core technologies work together.
Pillar 1: Optical Character Recognition (OCR) - Extracts all text content from creatives, including position, size, and formatting information. OCR excels at comprehensive text detection but can't classify element purpose.
Pillar 2: Machine Learning Image Classification - Identifies and labels visual elements (logo, hero image, call-to-action button, terms and conditions, background). Classification gives structure but not content understanding.
Pillar 3: Natural Language Processing (NLP) - Analyzes extracted text for semantic violations (designation mentions, non-inclusive language, alcohol references, prohibited claims). NLP understands content but lacks visual context.
Each technology has distinct strengths and limitations. The challenge lies in combining them to multiply strengths while minimizing compounded errors.
Here's the problem: combining three independent technologies with individual error rates creates multiplicative error. If OCR has 95% accuracy, classification has 92% accuracy, and NLP has 94% accuracy, naive combination yields:
This 18% error rate isn't acceptable for brand compliance. The solution lies in intelligent intersection rather than simple concatenation. The solution lies in intelligent intersection. OCR extracts all text with bounding boxes:
ML classification identifies element regions and labels:
Geometric intersection matches OCR text blocks with ML element regions through overlap calculation. This uses multiple algorithms to ensure accurate element association.
Geometric matching algorithms
Several computational geometry techniques match OCR text blocks with ML-classified element regions:
Point-in-polygon test (ray casting) - Determines if text center points fall within classified element boundaries using O(n) ray casting. Odd intersection count indicates point inside polygon; even count indicates outside.
Rectangle overlap calculation - Computes the percentage of overlap between two bounding boxes by finding the intersection area and dividing by the smaller box's area.
Line intersection (determinant method) - For rotated bounding boxes, uses 2x2 determinants to calculate line segment intersections. This method handles parallel lines gracefully without special cases.
Angle calculations - When matching rotated text blocks with classified elements, the system calculates relative angles to ensure orientation alignment (typically requiring <15° difference).
Perpendicular line calculation - For creating parallel boundaries around text regions, the system calculates perpendicular unit vectors by rotating the segment vector 90 degrees and normalizing by its Euclidean length.
Merging intersection results
Confidence-weighted filtering happens next. Only process elements meeting combined confidence thresholds:
Individual technology confidence > 90%
Geometric overlap > 70%
Combined confidence (minimum of individual scores) > 85%
This approach reduces error multiplication by rejecting low-confidence matches rather than compounding uncertainty. NLP semantic analysis completes the process. Apply NLP only to high-confidence text-element pairs:
Calibration mechanisms enable continuous improvement. Calibration happens through:
Overlap threshold tuning - Initial deployment used 60% overlap threshold, resulting in false positives where partial text overlap incorrectly associated unrelated elements. Analysis of 10,000 creatives determined 70% overlap optimal for balancing precision (minimize false positives) and recall (minimize false negatives).
Confidence threshold adaptation - Different element types exhibit different baseline confidence scores. CTA buttons consistently achieve 95%+ classification confidence, while decorative elements average 78%. We maintain element-type-specific thresholds rather than global thresholds.
Iterative testing - Each calibration adjustment undergoes A/B testing:
Process 1,000 creatives with current thresholds
Process same 1,000 with adjusted thresholds
Human expert review of differences
Adopt configuration minimizing false positives while maintaining recall
The rule engine for flexible compliance
After extracting and enriching creative data, the final component validates compliance through configurable rules. Traditional hard-coded validation logic becomes unmaintainable as brands add, modify, or remove guidelines. A declarative rule engine solves this problem.
We use a declarative rule engine built on the json-rules-engine library.
Built on the json-rules-engine library, the system extends basic boolean logic with custom operators for creative-specific evaluations.
Core principles
Declarative configuration - Rules defined in JSON, not code
Composable operations - Complex rules built from simple primitives
Extensible operators - Custom logic for spatial relationships, aggregations
Performance optimization - Compiled rule sets for repeated execution
Rules execute in two-phase workflows:
Phase 1 - Filter
Select relevant elements based on criteria:
What this filter does
Selects elements where
elementTypeis "text" OR "headline"AND where calculated
areaexceeds 0Stores results in
textElementsarray
Phase 2 - Aggregate
Perform calculations on filtered elements:
What this aggregation does
Sums
areavalues fromtextElementsGroups by creative
size(e.g., 1080x1920, 1200x628)Takes maximum sum per group OR minimum sum per group
Triggers violation if max exceeds 50% OR min falls below 30%
Here's a complete example.
A common requirement states: "Text elements must not overlap with person images." Implementation requires spatial relationship evaluation.
Creating a custom position intersection operator
Rule definition
Execution flow
Filter all text elements -> textElements array
Filter all person images ->
personImagesarrayFor each text element, check intersection with each person image
If any intersection exists, rule fails
Rules stored in the database enable runtime updates without deployment.
Rules stored in MongoDB enable runtime updates without deployment:
Brands can add new rules through UI without engineering involvement:
Designer defines requirement: "Logos must not exceed 8% of canvas"
System translates to rule JSON
Rule activates immediately for new creative evaluations
Historical creatives remain unaffected (rules apply prospectively)
Cost optimization strategies
AI-powered compliance systems involve significant computational expense. We've found that strategic optimization balances cost against user experience.
Two prediction modes are available:
Online prediction provides immediate feedback during design. Higher per-request cost (~$0.002 per creative), but enables interactive workflows. Best for real-time designer validation.
Batch prediction offers delayed feedback (15-30 minutes) at lower per-request cost (~$0.0003 per creative via batching). Requires accumulated workload. Best for overnight campaign validation and historical audits.
Hybrid approach combines both. Priority creatives (designer actively editing) use online prediction. Background validation (automated generations) uses batch. This reduces costs by ~60% compared to pure online.
Different deployment strategies suit different scales.
Managed ML services
Simplest deployment (Google AutoML, AWS SageMaker)
Highest cost ($0.50-$2.00 per 1000 predictions)
Minimal maintenance burden
Self-hosted models on Kubernetes
Custom model deployment
Lowest variable cost ($0.05-$0.15 per 1000 predictions)
Higher fixed cost (infrastructure, DevOps)
Optimal when: >100,000 validations/month
Cost crossover analysis
Rocketium's scale (10,000+ creatives/day, each requiring 2-3 model calls) justifies self-hosted infrastructure, achieving 73% cost reduction compared to managed services.
Results and the path forward
Future development roadmap
The compliance system continues evolving across multiple dimensions:
Advanced ML capabilities
Computer vision enhancement - Current image classification relies on pre-trained models with generic labels. Training domain-specific models on brand creative datasets would improve classification accuracy from 92% to 97%+, particularly for industry-specific elements (pharmaceutical disclaimers, financial risk statements).
Multimodal transformers - Future iterations will incorporate Vision-Language models (like CLIP, BLIP) that understand images and text jointly, enabling more sophisticated requirements: "Ensure promotional text does not appear over faces" requires simultaneous visual and semantic understanding.
User-generated rule authoring -
Current system requires technical knowledge to create rules. Planned natural language interface would enable:
Designer input "Make sure the discount badge doesn't cover the product"
System translation
This democratizes compliance management, eliminating bottlenecks from centralized governance teams.
Predictive compliance scoring - Rather than binary pass/fail, future system will provide probabilistic scoring:
"This creative has 87% compliance confidence. Primary risks: (1) Logo size in 82nd percentile may trigger review, (2) Headline character count approaching maximum threshold."
This allows proactive optimization before formal validation, reducing iteration cycles.
Cross-platform adaptation intelligence - As creatives adapt across platforms (Facebook, Google, Amazon), different compliance rules apply. System will automatically validate platform-specific requirements:
Facebook - Text-to-image ratio limits
Google Display - Prohibited content categories
Amazon Advertising - Product claim substantiation
Single creative generates platform-specific compliance reports, streamlining multi-channel campaign launches.
The compliance transformation
Traditional brand compliance relied on human expertise applied inconsistently across fragmented workflows. Manual review handles only 50-100 creatives per day at 85% accuracy. Rocketium's AI system processes 10,000+ creatives daily at 90%+ accuracy.
We've built a system that combines three capabilities. It learns from 200,000+ historical creatives to provide data-driven recommendations rather than arbitrary rules. It fuses OCR, machine learning, NLP, and computer vision to exceed individual component accuracy. Brands can define compliance rules through configuration, not code.
Enterprises can now scale creative production 100x while maintaining brand integrity and reducing legal risk. Real-time validation replaces slow manual review cycles. As creative operations accelerate through AI-generated content, intelligent compliance systems become essential.
Future iterations will incorporate multimodal transformers that simultaneously process visual and textual information. The mathematical foundation positions the system to absorb these enhancements without restructuring.
Rocketium processes over 200,000 creatives annually across enterprise brands spanning financial services, e-commerce, healthcare, and technology sectors. The dual-approach logo detection system processes 10,000+ logo validations daily with 95% accuracy for standard orientations and 87% accuracy for rotated/distorted scenarios. To learn more about implementing AI-powered brand compliance, visit rocketium.ai.
